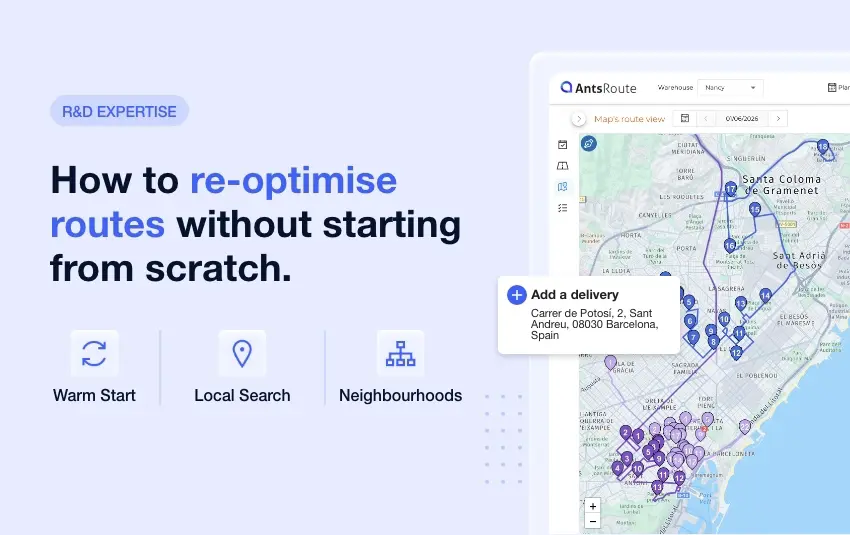
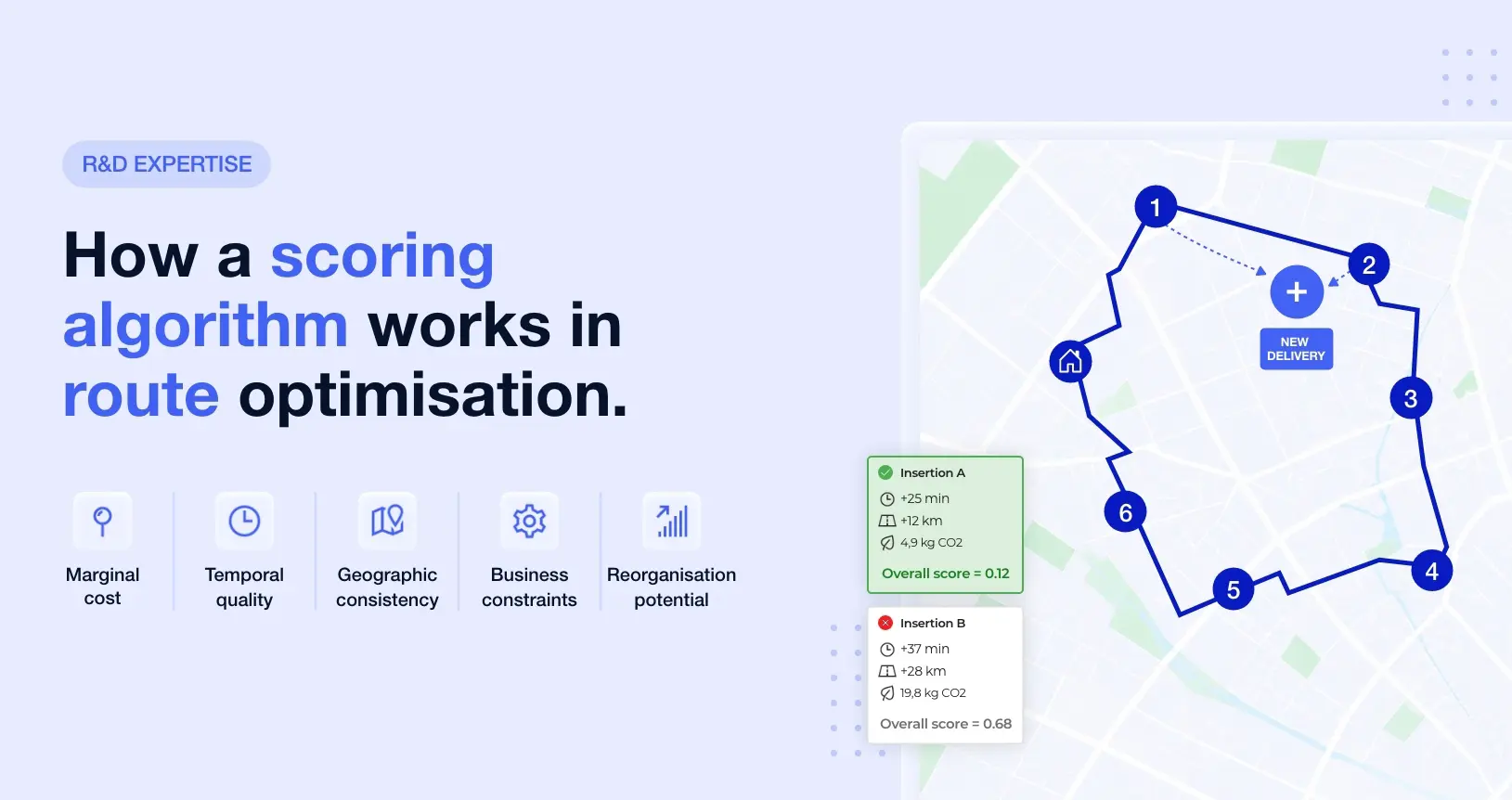
How a scoring algorithm works in route optimisation

Blog > Route optimisation > How a scoring algorithm works in route optimisation
How a scoring algorithm works in route optimisation
Published on 27 May 2026 • Reading time: 8 min read
In a route optimisation engine, the challenge is not simply to determine whether an insertion is feasible. The real objective is to determine whether that insertion represents a good operational decision.
This distinction is critical: in real-world systems, several insertions may be technically valid while producing very different outcomes. Some severely reduce schedule robustness. Others increase waiting times or gradually lock future flexibility for route reorganisation. In other words, feasibility alone is not enough.
This is precisely why modern optimisation engines rely on multi-criteria scoring mechanisms. At AntsRoute, scoring plays a central role in assessing and prioritising candidate insertions within an already constructed schedule.
What this article covers:
- Why scoring has become central to optimisation engines
- Why not all feasible insertions are equal
- The role of marginal cost in route evaluation
- Why temporal quality completely changes scoring
- Geographic consistency as a robustness criterion
- Hard constraints vs soft constraints: two different approaches
- Preserving future reorganisation capacity
- How scoring guides the engine’s exploration process
- Why a score must remain understandable and explainable
Scoring is an arbitration mechanism
In simplified approaches, an insertion is often assessed using a single criterion, such as additional distance, travel time or immediate cost. In real-world operations, however, this logic quickly becomes insufficient.
The engine must simultaneously arbitrate between several objectives that may sometimes conflict:
- reducing mileage;
- preserving time buffers;
- maintaining geographic consistency;
- complying with business constraints;
- limiting waiting times;
- preserving future reorganisation capacity;
- and avoiding overly fragile routes.
As Ammar Oulamara, Head of R&D at AntsRoute, explains:
“Scoring is not simply about finding the least expensive insertion. It is about finding the insertion that causes the least degradation to the overall quality of the schedule.”
This nuance fundamentally changes the way the engine is designed.
This article deliberately focuses on scoring and insertion evaluation mechanisms. For a broader overview of the challenges involved in route optimisation in last-mile logistics, you can also read our complete article on route optimisation. The challenge then becomes one of aggregation.
How do you compare two insertions when:
- the first slightly increases mileage;
- the second has a greater impact on time buffers;
- while the third creates more waiting time but preserves better geographic consistency?
To make these solutions comparable, the engine converts all these dimensions into a single scalar score capable of ranking candidate insertions.
The objective is not to artificially reduce the problem to a single metric, but to build a consistent arbitration mechanism between several heterogeneous operational costs.
Not all feasible insertions are equal
Let us consider a new task τ to be inserted into an already constructed multi-day schedule. The engine must then explore a decision space of the form: (day d) × (route rᵢ) × (position p). Each candidate triplet must then be evaluated.
Some insertions are immediately rejected:
- capacity exceeded;
- skill incompatibility;
- regulatory violation;
- temporal infeasibility.
But in most cases, several insertions remain feasible.
This is where scoring becomes central: it allows the engine to compare these solutions, measure their relative quality and rank the best candidates. The engine therefore does not operate according to a binary logic — feasible or impossible — but according to solution quality.
First layer of scoring: the marginal insertion cost
The first component of scoring is naturally the geographic cost. At AntsRoute, the engine notably evaluates the marginal cost introduced by adding a task using the following formula:
Δc = c(vₚ₋₁, τ) + c(τ, vₚ) − c(vₚ₋₁, vₚ)
This measure makes it possible to quantify the direct additional cost created by inserting a task between two consecutive vertices in a route. The lower this cost:
- the more geographically consistent the insertion;
- the more the route preserves its spatial compactness.
But this component represents only part of the overall score.
As Ammar Oulamara points out:
“Mileage cost alone is a very poor indicator of quality in highly constrained routes.”
The score must incorporate the temporal quality of the route
In VRPTW (Vehicle Routing Problem with Time Windows) scenarios, time constraints become dominant. An insertion may:
- increase waiting times;
- reduce time buffers;
- densify certain time slots;
- or significantly reduce the temporal stability of the schedule.
The engine therefore also penalises unnecessary waiting times according to the following objective:
min Σᵢ max(0, eᵢ − tᵢ)
In this formulation, eᵢ represents the opening of the time window, while tᵢ corresponds to the estimated arrival time.
These waiting times play an important role in scoring because they progressively reduce operational productivity, route density and the future ability to absorb disruptions.
One of the main challenges of multi-criteria scoring lies in the heterogeneity of the metrics being handled. Additional kilometres, waiting times, constraint penalties and workload imbalances neither share the same units nor the same orders of magnitude. The engine must therefore normalise these different dimensions to prevent one criterion from artificially dominating the others purely because of its numerical scale.
This normalisation then makes it possible to objectively compare insertions with very different operational profiles. The engine can subsequently aggregate these normalised components into a global scalar score used to rank candidate insertions.
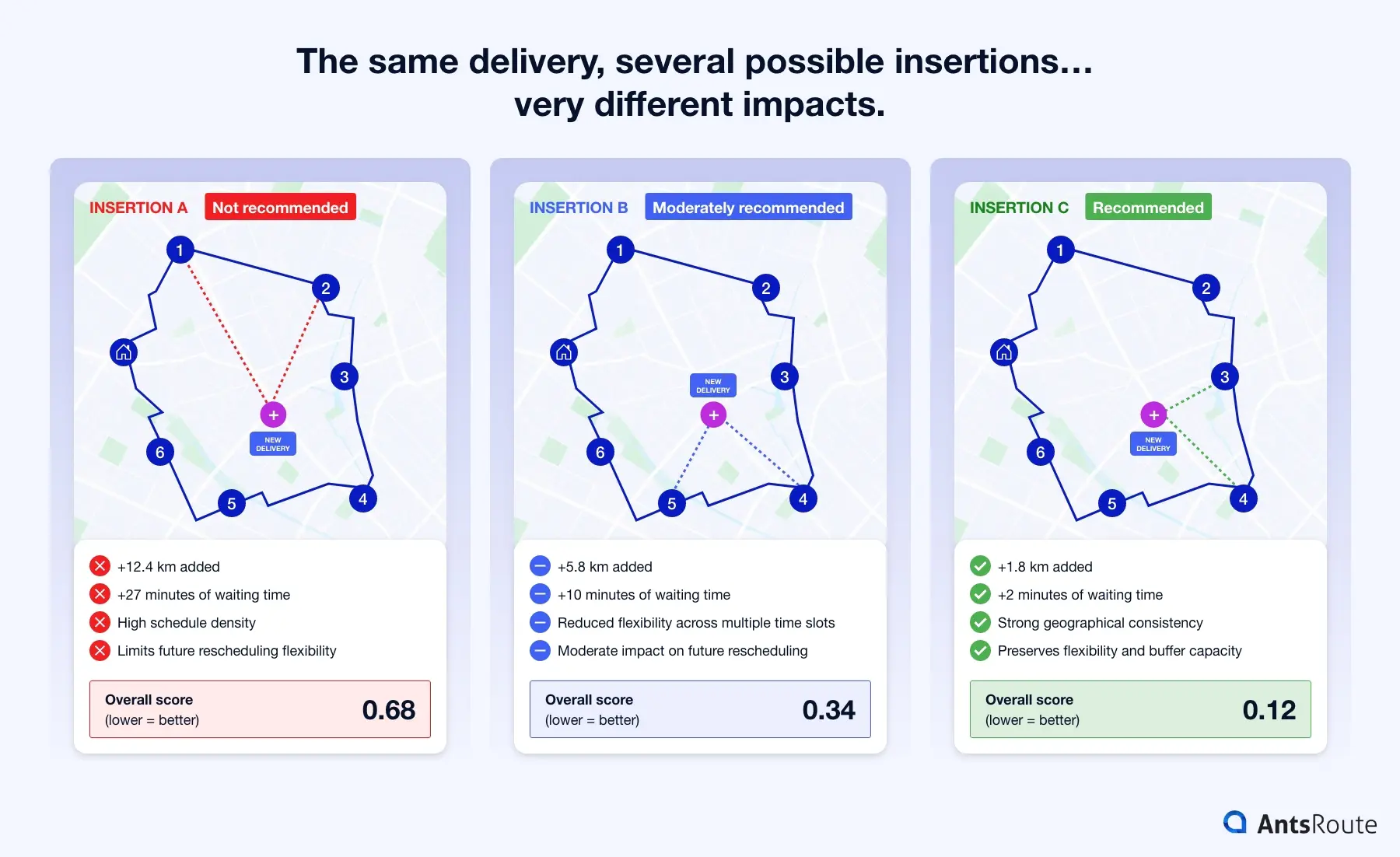
Comparison of several candidate insertions within a dynamic route to illustrate the role of multi-criteria scoring in assessing the operational quality of schedules.
The score also measures geographic consistency
A route may be mathematically optimised while still remaining difficult to operate in the field. This is particularly true of fragmented routes featuring:
- frequent overlaps;
- scattered geographic areas;
- unnecessary back-and-forth journeys;
- poorly structured allocation of tasks.
At AntsRoute, the scoring system therefore also incorporates spatial compactness criteria.
The objective is to encourage:
- geographic clustering of customers;
- route continuity;
- and operational readability of the schedule.
As Ammar Oulamara explains:
“A geographically consistent route is often more robust and easier to operate in practice.”
Hard constraints and soft constraints: two very different approaches
One of the central elements of scoring lies in the distinction between strict constraints and penalised constraints.
Some violations are forbidden and lead to the immediate rejection of the solution by the engine, including:
- skill incompatibility;
- regulatory breaches;
- impossible pickup & delivery sequences;
- vehicle capacity exceeded.
By contrast, other degradations remain technically acceptable, even though they reduce the overall quality of the schedule. The engine therefore incorporates them as penalties within the score. This applies for example to:
- excessive waiting times;
- temporal overloads;
- low robustness;
- imbalances between routes.
However, not all degradations have the same operational impact. A slight increase in route density may remain acceptable. By contrast, an excessive reduction in time buffers or a heavy concentration of critical tasks within the same time slot can significantly reduce the overall robustness of the schedule.
The engine therefore applies progressive penalties whose intensity depends on the estimated severity of the degradation caused by the insertion. This approach avoids overly rigid reasoning while still enabling intelligent comparisons between several imperfect solutions.
Finally, not all criteria carry the same weight in the final evaluation. Depending on the operational context, certain priorities may become dominant:
- temporal stability;
- mileage reduction;
- geographic density;
- capacity to absorb urgent requests.
The role of weighting is precisely to reflect these business priorities in the score calculation. The engine is therefore not searching for a universal optimum, but for a compromise aligned with the real operational objectives.

Illustration of the difference between strict constraints and penalisable constraints in the multi-criteria scoring used by modern route optimisation engines.
The score must also measure future reorganisation potential
One of the most difficult aspects of dynamic systems concerns the schedule’s future capacity to evolve. Some insertions may appear highly efficient in the short term, yet subsequently make routes far more difficult to re-optimise. This can notably result in:
- the disappearance of time buffers;
- saturation of certain resources;
- neighbourhood lock-in;
- heavy local densification.
At AntsRoute, the scoring system therefore also incorporates the local improvement potential of candidate insertions. As Ammar Oulamara points out:
“A good insertion must also preserve the engine’s future ability to reorganise the schedule efficiently.”
In a dynamic environment, an insertion’s score is never fixed. It continuously evolves as:
- the schedule becomes denser;
- new constraints emerge;
- or certain time buffers disappear.
This approach is essential in real-time environments.
Scoring is also used to guide algorithmic exploration
Scoring is not only used to rank solutions: it also helps direct the engine’s computational effort. Not all insertions deserve the same calculation budget.
The least promising solutions are discarded quickly through limited local evaluations. By contrast, the insertions achieving the highest scores subsequently benefit from:
- deeper neighbourhood exploration;
- local search mechanisms;
- or more computationally expensive improvement strategies.
Scoring therefore becomes a genuine prioritisation mechanism for the search space. Once the evaluation phase is complete, candidate time slots can be ranked according to their operational quality in order to automatically guide the selection of the most relevant insertions.
This prioritisation is essential to maintain:
- response times compatible with real-time operations;
- while still preserving an excellent level of optimisation quality.
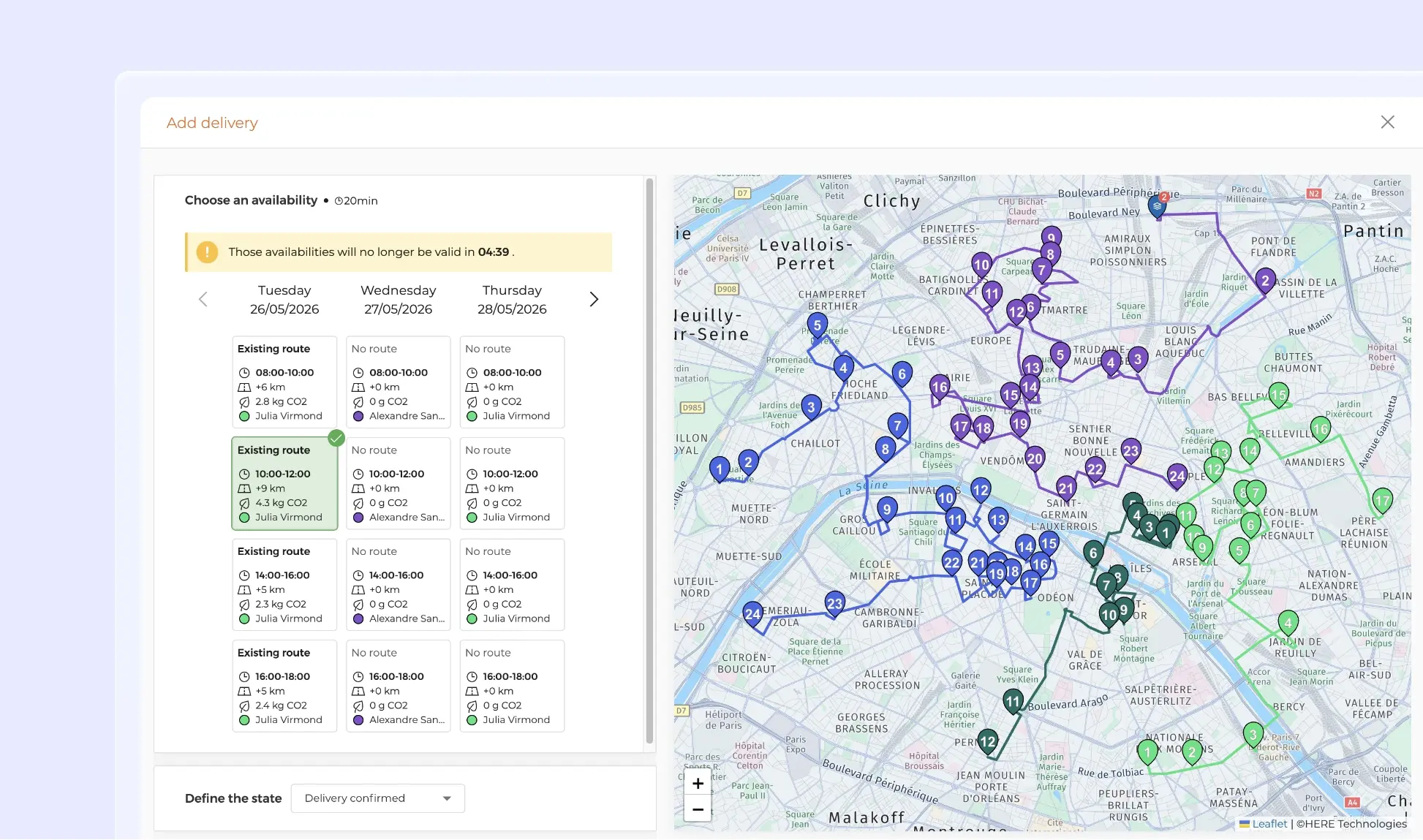
Adding a delivery with availability search in AntsRoute.
Why a score must remain explainable
In many optimisation systems, one of the main issues concerns decision opacity. An engine that produces a solution without being able to explain why one insertion was selected, why another was rejected, or which constraints influenced the arbitration becomes difficult to operate in practice.
At AntsRoute, the scoring system is therefore designed to remain interpretable. The main components of the score remain readable and analysable, including:
- the marginal cost;
- the penalties applied;
- feasibility;
- temporal quality;
- reorganisation potential.
This explainability not only helps users better understand the trade-offs made by the engine, but also strengthens operational teams’ trust in the proposed decisions.
Conclusion
In a modern route optimisation engine, scoring is not simply about calculating additional distance. It acts as a multi-criteria evaluation system capable of measuring:
- the geographic quality of an insertion;
- its temporal robustness;
- its business feasibility;
- its operational consistency;
- and its future impact on the schedule.
This approach enables the engine to move beyond purely local reasoning in order to rank solutions at the scale of the overall system. Because in last-mile operations, a good decision is not simply a feasible one: it is a decision capable of sustainably preserving the operational balance of the schedule.
WRITTEN BY

Marie Henrion
At AntsRoute, Marie has been the marketing manager since 2018. With a focus on last-mile logistics, she produces content that simplifies complex topics such as route optimization, the ecological transition, and customer satisfaction.
Free 7-day trial | No credit card required
Contenu
- Scoring is an arbitration mechanism
- Not all feasible insertions are equal
- First layer of scoring: the marginal insertion cost
- The score must incorporate the temporal quality of the route
- The score also measures geographic consistency
- Hard constraints and soft constraints: two very different approaches
- The score must also measure future reorganisation potential
- Scoring is also used to guide algorithmic exploration
- Why a score must remain explainable
- Conclusion